Postgres HA using repmgr
This comprehensive article provides a detailed, easy-to-follow guide on setting up a high-availability PostgreSQL database cluster using repmgr.

We are going to discuss how we set up high availability across our network. This will be split up to several parts which touch various components that I personally run in my networks.
All the commands here are run on Ubuntu 22.04 server minimal and use the default values. All machines need to have docker running, though you can also just run parts of it dockerised and others on physical machines.
DO NOTE: I did not choose to stick with repmgr and prefer using pg_auto_failover because it is much more automated in the same of getting clusters up and sync between the various components
Introduction
Everything I do runs over an overlay network. I use NetBird for this and wrote a complete guide that can be found here. Alternatively, you can also use the likes of tailscale.
Enable UFW to allow connections only from Tailscale interface, once you run the last command sudo ufw enable tou may get dropped off if you are not connected to the Tailscale network. You will have to reconnect again, but this time to the Tailscale IP of the machine, so make sure to note or retrieve your Tailscale IP beforehand.
1
2
3
4
5
6
7
8
9
10
11
# For tailscale run the command below
sudo ufw allow in on tailscale0
# For NetBird run the command below
sudo ufw allow in on wt0
# Firewall defaults below with frowarding allowed
sudo ufw default deny incoming
sudo ufw default allow outgoing
sudo ufw route allow from 100.64.0.0/10 to any
sudo ufw enable
Install Postgresql
We will first install postgresql repositories, follow the instructions for your OS below.
Once you have added the correct repositories, you should run:
1
sudo apt install postgresql-15
Postgresql HA using repmgr
Some links may be affiliate links that keep this site running.
Ensure the database is up and running
You will need install postgres and run the command below on all the servers that you are replicating, this will set up
1
sudo systemctl start postgresql.service
Command Breakdown:
-
sudo: This is a command used in Unix-like operating systems to allow a user to run programs with the security privileges of another user, typically the superuser (or root). It stands for “superuser do”. By using sudo, you’re executing the following command with elevated privileges, typically requiring authentication (entering your password). -
systemctl: This is a command-line tool used to interact with systemd, which is a system and service manager for Linux. systemctl allows you to manage system services, such as starting, stopping, restarting, enabling, or disabling them. -
start: This is an option for systemctl that tells it to start the specified service. -
postgresql.service: This is the name of the service you want to start. In this case, it’s the PostgreSQL service. PostgreSQL is a powerful, open-source relational database management system (RDBMS) widely used for handling large amounts of data.
Check the version you are running
1
pg_config --version
The command pg_config –version is used to retrieve the version of PostgreSQL installed on your system. When you run this command in the terminal, it will output the version number of PostgreSQL.
For example, if you run pg_config –version and you have PostgreSQL version 14 installed, the output might be:
1
PostgreSQL 14.0
This command is particularly useful for checking the version of PostgreSQL installed on your system, especially when you need to verify compatibility or check for updates.
You should check your data directory location using the command
sudo -u postgres psql -c "show data_directory;"; , in my case it is/var/lib/postgresql/15/main, and so it is referred that way throughout the documentation. it may be different for you.
Configure Primary node
Find the following lines, and change the listening address to your Netbird/tailscale address, to get the tailscale address you can run tailscale ip or get it from your dashboard, for NetBird run netbird status or refer to dashboard.
Edit the following file (replace your version ID):
1
sudo nano /etc/postgresql/<Version e.g. 15>/main/postgresql.conf
Find the following line and replace it with your address we found earlier:
1
listen_addresses = 'your_primary_IP_address'
Create a replication role
Login to the postgresql prompt
1
sudo -u postgres psql
Run the following commands, replace the username and password with your credentials, make sure to keep it safe in your password manager as you’ll need it to authenticate with the primary.
1
2
CREATE ROLE username WITH REPLICATION PASSWORD 'replicationpass' LOGIN;
\q
Setting up Postgres Primary
Edit the configuration file below:
1
sudo nano /etc/postgresql/<Version e.g. 15>/main/pg_hba.conf
At the bottom of the file add the following line, it will allow any IP in the private (Tailscale/NetBird) network to connect using the replication user.
1
2
# Tailscale/NetBird replication configuration
host replication replication 100.64.0.0/10 md5
Important note, if you want to remove the need for a password, instead of md5 write trust
Restart postgresql service
1
sudo systemctl restart postgresql
Setting up a replica
After installing postgresql just like we did earlier, we want to clear the data directory.
1
2
3
sudo -u postgres rm -r /var/lib/postgresql/15/main
sudo -u postgres mkdir /var/lib/postgresql/15/main
sudo -u postgres chmod 700 /var/lib/postgresql/15/main
Now that the directory is empty, we will copy over the configuration and data files from the primary server, we do that using an internal utility named pg_basebackup.
1
sudo -u postgres pg_basebackup -h <Tailscale IP address of primary> -p 5432 -U replication -D /var/lib/postgresql/15/main -Fp -Xs -R
Command breakdown:
-
pg_basebackupis the command used to create a base backup of a PostgreSQL database. -
-hspecifies the hostname or IP address of the machine on which the PostgreSQL server is running. -
-p5432 specifies the port on which the PostgreSQL server is listening. The default port for PostgreSQL is 5432. -
-Ureplication specifies the name of the database user that the pg_basebackup utility should use to connect to the database server. In this case, it’s the replication user. This user needs to have replication privileges. -
-D/var/lib/postresql/15/main specifies the directory to which the base backup will be written. In this case, it’s /var/lib/postresql/15/main. -
-Fpsets the format of the backup. p stands for plain, meaning that the backup will be in plain file system format, with the files in the backup set appearing much as they would in a normal data directory. -
-Xsspecifies the method of handling transaction logs (WAL files). s stands for “stream”, meaning that while the backup is created, transaction log records will be streamed back to the base backup client and be included in the backup as a separate tar file (pg_wal.tar). This option is used to ensure that the backup is consistent and able to be restored to a particular point in time. -
-Rcreates a recovery.conf file (for PostgreSQL versions prior to 12) or a standby.signal file and necessary postgresql.auto.conf settings (for PostgreSQL versions 12 and later) in the output directory, which enables the backup to be set up as a standby that will start streaming changes from the master after the backup is restored.
In a nutshell, this command is creating a physical backup of a PostgreSQL database located on the server through Tailscale, using the replication user. The backup is created in plain file format and it includes the transaction log files. A recovery configuration is also created for setting up a standby database.
Restart service
1
sudo systemctl restart postgresql
Confirm it is working by running the following commands on your primary node
1
2
sudo -u postgres psql
SELECT client_addr, state FROM pg_stat_replication;
Repeat the steps for the other replicas if you want to add more.
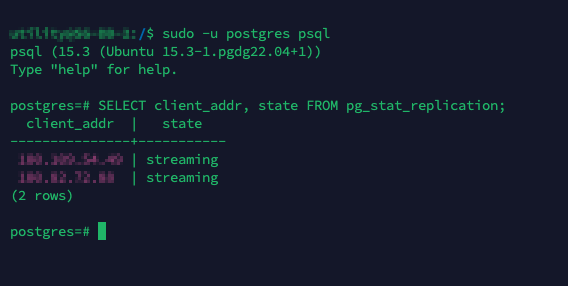 Postgresql/repmgr Replication state
Postgresql/repmgr Replication state
Setting asynchronous mode
Edit the pstgresql.conf file on the primary server
1
sudo nano /etc/postgresql/15/main/postgresql.conf
Change the following lines, these are not bunched together in the file, search is your friend.
1
max_wal_senders = 10
The line above defines the max amount of standby srevers you will be able to add, so define it wisely.
1
max_replication_slots = 11
We will need to set this up if we plan to use slotted replication (which we do in the automated failover portion later on in the article)
1
wal_keep_size = 128
The line above defines the disk space that will be reserved for log segments for standby servers, don’t set it too high as you might consume more disk space than needed; At the same time, keep in mind that setting this too low will end up forcing your standby servers to initiate a full resync as logs have been missed.
1
wal_log_hints = on
This setting makes sure that during a failover, the replica is consistent with the primary.
1
hot_standby = on
Defines the standby mode, this means that your clients are allowed to run read only queries against your replicas. Offloading any load that may be generated querying directly the primary. You can save the configuration file.
Testing your configuration
The command below will show us the streaming and replication status to the other replicas.
1
sudo -u postgres psql -x -c "select * from pg_stat_replication"
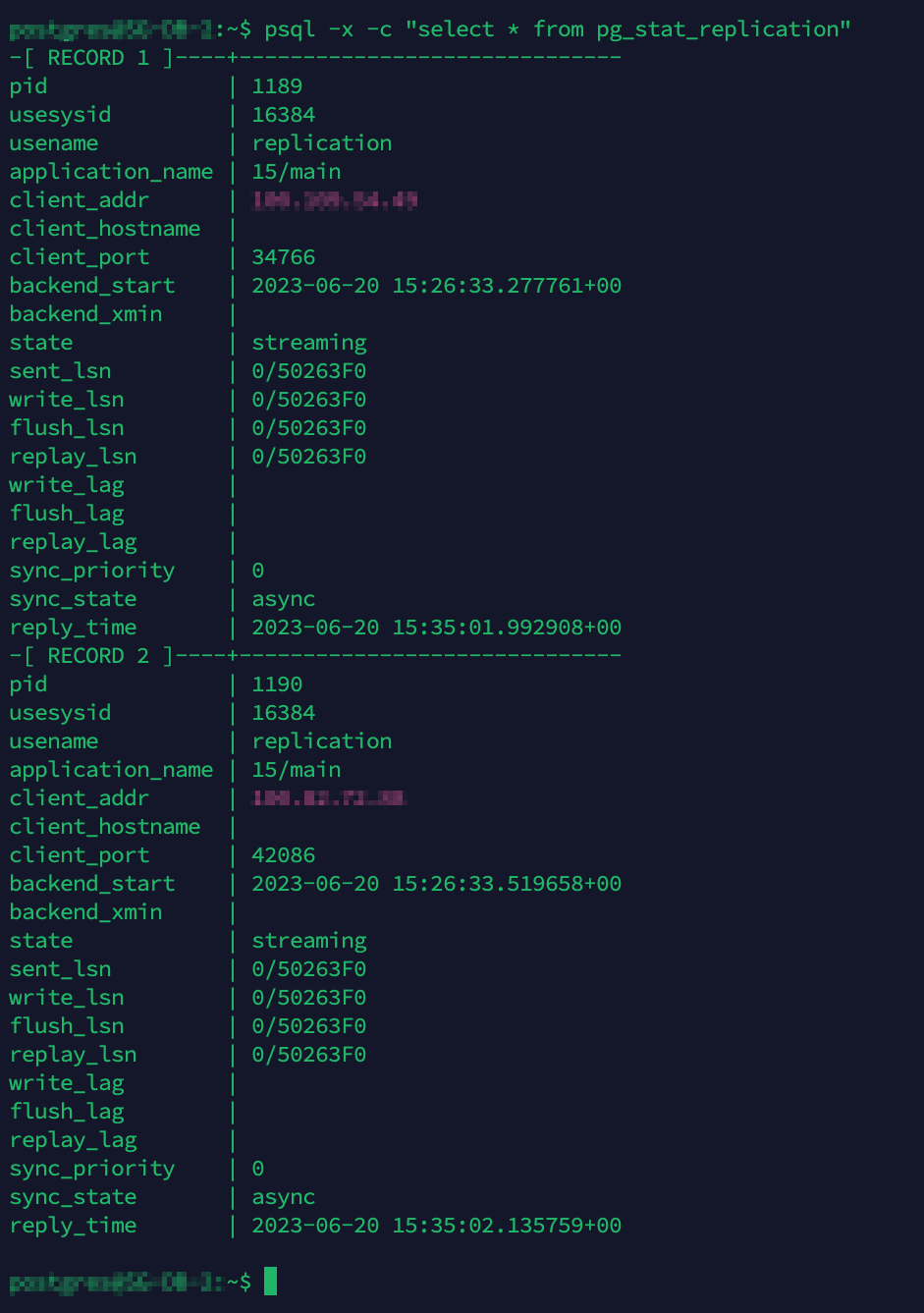 Replication status
Replication status
All the steps above gave us replication, this will make sure that the replicas are available for read-only if the primary is down. If you want to continue running in this configuration and wait for the primary to come back up that’s completely fine! If you’d like for it to continue functioning and write, you will need to promote your replica to a primary manually.
Do not run the command below without first shutting down your primary postgresql service
1
sudo -u postgres pg_ctl promote -D /path/to/data/directory
This command promotes the local standby node to become the new primary. It should be run on the standby node that you want to promote.
Make sure you have sourced the repmgr environment before running this command if needed, this assumes that you have configured repmgr properly and have the necessary permissions to execute repmgr commands. It’s also important to ensure that you’re promoting the correct replica.
Replication Manager for Postresql clusters
Of course you wouldn’t want to manually promote the primary everytime you have the database go down, and so there is an automated solution out there! We will be looking at repmgr.
Make sure your primary postgres.conf` file has the following change:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
#Allow monitoring for repmgr
shared_preload_libraries = 'repmgr'
...
listen_address = <Tailscale IP address>
...
max_wal_senders = 10
max_replication_slots = 10
...
wal_level = hot_standby
...
hot_standby = on
...
archive_mode = on
archive_command = '/bin/true'
-
listen_address: Allows the PostgreSQL server to accept connections from any address, making it possible for the primary server and standby servers to communicate with each other. -
max_wal_sendersand max_replication_slots: These parameters control the number of connections to the primary server that can be made by standby servers to receive WAL data. They ensure that the standby servers are not overwhelmed with data and that the primary server can efficiently send WAL data to the standby servers. -
wal_levelandhot_standby: These settings enable the primary server to write WAL data that is required for standby servers to work correctly. By setting hot_standby to on, the standby servers can be used for read-only queries, allowing for more efficient use of resources. -
archive_modeandarchive_command: These settings are used to ensure that WAL files are archived and available for disaster recovery scenarios. archive_mode enables archiving of WAL files, while archive_command specifies how the archived files should be handled. In the provided configuration, archive_command is set to /bin/true to ensure that the archived files are not actually saved to disk, but are still available for disaster recovery purposes.
Start the postgresql system service, switch to the postgres user and issue the user creation commands:
1
2
3
4
sudo systemctl restart postgresql
sudo su - postgres
createuser -s repmgr
createdb repmgr -O repmgr
edit /etc/postgresql/15/main/pg_hba.conf and append at the end:
1
2
host replication repmgr 100.64.0.0/10 trust
host repmgr repmgr 100.64.0.0/10 trust
You can also put a specific Tailscale IP there with the subnet of /32 if you only want specific machines to be able to communicate with each other.
Configurating Cluster using repmgr
Register the primary server into the cluster
exit from the postgres user using exit
create a repmgr.conf using sudo nano /etc/repmgr.conf and paste the configuration below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
node_id=1
node_name=dbhost
conninfo='host=dbhost user=repmgr dbname=repmgr connect_timeout=2'
data_directory='/var/lib/postgresql/data'
failover=automatic
promote_command='repmgr -f /etc/repmgr.conf standby promote --log-to-file'
follow_command='repmgr -f /etc/repmgr.conf standby follow --log-to-file --upstream-node-id=%n'
log_level=NOTICE
primary_visibility_consensus=true
standby_disconnect_on_failover=true
repmgrd_service_start_command='sudo /usr/bin/systemctl start repmgrd.service'
repmgrd_service_stop_command='sudo /usr/bin/systemctl stop repmgrd.service'
service_start_command='sudo /usr/bin/systemctl start postgresql.service'
service_stop_command='sudo /usr/bin/systemctl stop postgresql.service'
service_restart_command='sudo /usr/bin/systemctl restart postgresql.service'
service_reload_command='sudo /usr/bin/systemctl reload postgresql.service'
monitoring_history=yes
log_status_interval=60
Register the node to the cluster running repmgr -f /etc/repmgr.conf primary register , and you should see the following:
1
2
3
4
5
utility@dbhost:~$ repmgr -f /etc/repmgr.conf primary register
INFO: connecting to primary database...
NOTICE: attempting to install extension "repmgr"
NOTICE: "repmgr" extension successfully installed
NOTICE: primary node record (ID: 1) registered
Check your cluster using the command repmgr -f /etc/repmgr.conf cluster show and you should see:
| ID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string |
|---|---|---|---|---|---|---|---|---|
| 1 | dbhost | primary | * running | default | 100 | 1 | host=dbhost user=repmgr dbname=repmgr connect_timeout=2 |
#### Set up Secondary Server
With the primary server up and running and waiting for standby servers to join the cluster, the next step is to clone the primary server to create a standby server. This standby server will serve as a replica of the primary server, allowing it to operate in read-only mode and receive all changes made to the primary server. Once the standby server is registered with the cluster, it will be able to synchronize data with the primary server and remain in a “hot standby” state, ready to take over as the primary server in the event of a failover. This will help ensure high availability and reliability for the PostgreSQL cluster, as well as provide increased read scalability by allowing multiple read replicas to be added to the cluster.
1
sudo su - postgres
check you have connectivity:
1
psql 'host=<Primary internal IP address> user=repmgr dbname=repmgr connect_timeout=2'
create a clone from the primary server to act as a standby server, create a file repmgr.conf at /etc/postgresql/15/main with this content:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
node_id=2
node_name=dbhost2
conninfo='host=dbhost2 user=repmgr dbname=repmgr connect_timeout=2'
data_directory='/var/lib/postgresql/data'
failover=automatic
promote_command='repmgr -f /etc/repmgr.conf standby promote --log-to-file'
follow_command='repmgr -f /etc/repmgr.conf standby follow --log-to-file --upstream-node-id=%n'
log_level=NOTICE
priority=80
primary_visibility_consensus=true
standby_disconnect_on_failover=true
repmgrd_service_start_command='sudo /usr/bin/systemctl start repmgrd.service'
repmgrd_service_stop_command='sudo /usr/bin/systemctl stop repmgrd.service'
service_start_command='sudo /usr/bin/systemctl start postgresql.service'
service_stop_command='sudo /usr/bin/systemctl stop postgresql.service'
service_restart_command='sudo /usr/bin/systemctl restart postgresql.service'
service_reload_command='sudo /usr/bin/systemctl reload postgresql.service'
monitoring_history=yes
log_status_interval=60
Lets change folders to where are postgres executables are:
1
cd /etc/postgresql/15/main
Now we are ready to do a dry run for our configuration.
1
repmgr -h dbhost2 -U repmgr -d repmgr -f /etc/repmgr.conf standby clone --dry-run
If all went well, then you should see the lines below in your code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
postgres@dbhost2:/etc/postgresql/15/main$ repmgr -h dbhost -U repmgr -d repmgr -f /etc/repmgr.conf standby clone --dry-run
NOTICE: destination directory "/var/lib/postgresql/data" provided
INFO: connecting to source node
DETAIL: connection string is: host=dbhost2 user=repmgr dbname=repmgr
DETAIL: current installation size is 29 MB
INFO: "repmgr" extension is installed in database "repmgr"
INFO: replication slot usage not requested; no replication slot will be set up for this standby
INFO: parameter "max_wal_senders" set to 10
NOTICE: checking for available walsenders on the source node (2 required)
INFO: sufficient walsenders available on the source node
DETAIL: 2 required, 10 available
NOTICE: checking replication connections can be made to the source server (2 required)
INFO: required number of replication connections could be made to the source server
DETAIL: 2 replication connections required
WARNING: data checksums are not enabled and "wal_log_hints" is "off"
DETAIL: pg_rewind requires "wal_log_hints" to be enabled
NOTICE: standby will attach to upstream node 1
HINT: consider using the -c/--fast-checkpoint option
INFO: would execute:
pg_basebackup -l "repmgr base backup" -D /var/lib/postgresql/data -h dbhost2 -p 5432 -U repmgr -X stream
INFO: all prerequisites for "standby clone" are met
If you have can see the last line where it reads INFO: all prerequisites for "standby clone" are met
then you can continue and execute the replication command:
1
repmgr -h dbhost2 -U repmgr -d repmgr -f /etc/repmgr.conf standby clone
The log should read as follows:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
NOTICE: destination directory "/var/lib/postgresql/data" provided
INFO: connecting to source node
DETAIL: connection string is: host=dbhost2 user=repmgr dbname=repmgr
DETAIL: current installation size is 29 MB
INFO: replication slot usage not requested; no replication slot will be set up for this standby
NOTICE: checking for available walsenders on the source node (2 required)
NOTICE: checking replication connections can be made to the source server (2 required)
WARNING: data checksums are not enabled and "wal_log_hints" is "off"
DETAIL: pg_rewind requires "wal_log_hints" to be enabled
INFO: creating directory "/var/lib/postgresql/data"...
NOTICE: starting backup (using pg_basebackup)...
HINT: this may take some time; consider using the -c/--fast-checkpoint option
INFO: executing:
pg_basebackup -l "repmgr base backup" -D /var/lib/postgresql/data -h dbhost2 -p 5432 -U repmgr -X stream
NOTICE: standby clone (using pg_basebackup) complete
NOTICE: you can now start your PostgreSQL server
HINT: for example: pg_ctl -D /var/lib/postgresql/data start
HINT: after starting the server, you need to register this standby with "repmgr standby register"
Edit the config postgresql.conf and set the data director to your new cloned location of data_directory = '/var/lib/postgresql/data', make sure to change your listen_address = '*' and add shared_preload_libraries = 'repmgr' to your configuration.
For pg_gba.conf add the following:
1
2
host replication repmgr 100.64.0.0/10 trust
host repmgr repmgr 100.64.0.0/10 trust
{. file=”/etc/postgresql/15/main/pg_hba.conf”}
Start the standby server systemctl restart postgresql
Register standby
Register the standby using the command
1
repmgr -f /etc/repmgr.conf standby register
You should see the following log:
utility@dbhost2:~$ repmgr -f /etc/repmgr.conf standby register
INFO: connecting to local node "dbhost2" (ID: 2)
INFO: connecting to primary database
WARNING: --upstream-node-id not supplied, assuming upstream node is primary (node ID: 1)
If you would like to see the available cluster nodes, you should use the command:
1
repmgr -f /etc/repmgr.conf cluster show
It will generate the following output for you:
| ID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string |
|---|---|---|---|---|---|---|---|---|
| 1 | dbhost | primary | * running | default | 100 | 1 | host=dbhost user=repmgr dbname=repmgr connect_timeout=2 | |
| 2 | dbhost2 | standby | running | dbhost2 | default | 50 | 1 | host=dbhost2 user=repmgr dbname=repmgr connect_timeout=2 |
Adding more replicas
Repeat the steps above for your third host, changing the appropriate values, once done, you should see all servers added. Make sure to change priority=80 in your configuration.
| ID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string |
|---|---|---|---|---|---|---|---|---|
| 1 | dbhost | primary | * running | default | 100 | 1 | host=dbhost user=repmgr dbname=repmgr connect_timeout=2 | |
| 2 | dbhost2 | standby | running | dbhost2 | default | 50 | 1 | host=dbhost2 user=repmgr dbname=repmgr connect_timeout=2 |
| 3 | dbhost3 | standby | running | dbhost3 | default | 80 | 1 | host=dbhost3 user=repmgr dbname=repmgr connect_timeout=2 |
To enable monitoring and automatic failover handling, we need to set up repmgrd on all the PostgreSQL nodes (pg1, pg2 and pg3).
Start by logging into each server and registering them with repmgrd using the following command:
1
repmgrd -f /etc/repmgr.conf -d
Testing
Stop the service of one of your severs and take a look at the changes of roles, try stopping the primary and see what happens.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
utility@dbhost:~$ sudo systemctl stop postgresql
utility@dbhost:~$ [2023-06-24 01:18:56] [WARNING] unable to ping "host=dbhost user=repmgr dbname=repmgr connect_timeout=2"
[2023-06-24 01:18:56] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2023-06-24 01:18:56] [WARNING] connection to node "dbhost" (ID: 1) lost
[2023-06-24 01:18:56] [DETAIL]
FATAL: terminating connection due to administrator command
SSL connection has been closed unexpectedly
[2023-06-24 01:18:56] [INFO] attempting to reconnect to node "dbhost" (ID: 1)
[2023-06-24 01:18:56] [ERROR] connection to database failed
[2023-06-24 01:18:56] [DETAIL]
connection to server at "dbhost" (xxx.xxx.xxx.xxx), port 5432 failed: Connection refused
Is the server running on that host and accepting TCP/IP connections?
[2023-06-24 01:18:56] [DETAIL] attempted to connect using:
user=repmgr connect_timeout=2 dbname=repmgr host=dbhost fallback_application_name=repmgr options=-csearch_path=
[2023-06-24 01:18:56] [WARNING] reconnection to node "dbhost" (ID: 1) failed
[2023-06-24 01:18:56] [WARNING] unable to connect to local node
[2023-06-24 01:18:56] [INFO] checking state of node 1, 1 of 6 attempts
[2023-06-24 01:18:56] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=dbhost fallback_application_name=repmgr"
[2023-06-24 01:18:56] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2023-06-24 01:18:56] [INFO] sleeping 10 seconds until next reconnection attempt
[2023-06-24 01:19:06] [INFO] checking state of node 1, 2 of 6 attempts
[2023-06-24 01:19:06] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=dbhost fallback_application_name=repmgr"
[2023-06-24 01:19:06] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2023-06-24 01:19:06] [INFO] sleeping 10 seconds until next reconnection attempt
[2023-06-24 01:19:16] [INFO] checking state of node 1, 3 of 6 attempts
[2023-06-24 01:19:16] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=dbhost fallback_application_name=repmgr"
[2023-06-24 01:19:16] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2023-06-24 01:19:16] [INFO] sleeping 10 seconds until next reconnection attempt
[2023-06-24 01:19:26] [INFO] checking state of node 1, 4 of 6 attempts
[2023-06-24 01:19:26] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=dbhost fallback_application_name=repmgr"
[2023-06-24 01:19:26] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2023-06-24 01:19:26] [INFO] sleeping 10 seconds until next reconnection attempt
[2023-06-24 01:19:36] [INFO] checking state of node 1, 5 of 6 attempts
[2023-06-24 01:19:36] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=dbhost fallback_application_name=repmgr"
[2023-06-24 01:19:36] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2023-06-24 01:19:36] [INFO] sleeping 10 seconds until next reconnection attempt
[2023-06-24 01:19:46] [INFO] checking state of node 1, 6 of 6 attempts
[2023-06-24 01:19:46] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=dbhost fallback_application_name=repmgr"
[2023-06-24 01:19:46] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2023-06-24 01:19:46] [WARNING] unable to reconnect to node 1 after 6 attempts
[2023-06-24 01:19:46] [NOTICE] unable to connect to local node, falling back to degraded monitoring
[2023-06-24 01:19:46] [WARNING] unable to ping "host=dbhost user=repmgr dbname=repmgr connect_timeout=2"
[2023-06-24 01:19:46] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2023-06-24 01:19:46] [ERROR] unable to determine if server is in recovery
[2023-06-24 01:19:46] [DETAIL] query text is:
SELECT pg_catalog.pg_is_in_recovery()
[2023-06-24 01:19:46] [WARNING] unable to determine node recovery status
[2023-06-24 01:19:48] [WARNING] unable to ping "host=dbhost user=repmgr dbname=repmgr connect_timeout=2"
[2023-06-24 01:19:48] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2023-06-24 01:19:48] [WARNING] connection to node "dbhost" (ID: 1) lost
[2023-06-24 01:19:48] [DETAIL]
connection pointer is NULL
On the standby you will see:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
utility@dbhost2:~$ [2023-06-24 01:18:56] [WARNING] unable to ping "host=dbhost user=repmgr dbname=repmgr connect_timeout=2"
[2023-06-24 01:18:56] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2023-06-24 01:18:56] [WARNING] unable to connect to upstream node "dbhost" (ID: 1)
[2023-06-24 01:18:56] [INFO] checking state of node "dbhost" (ID: 1), 1 of 6 attempts
[2023-06-24 01:18:56] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=dbhost fallback_application_name=repmgr"
[2023-06-24 01:18:56] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2023-06-24 01:18:56] [INFO] sleeping up to 10 seconds until next reconnection attempt
[2023-06-24 01:19:06] [INFO] checking state of node "dbhost" (ID: 1), 2 of 6 attempts
[2023-06-24 01:19:06] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=dbhost fallback_application_name=repmgr"
[2023-06-24 01:19:06] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2023-06-24 01:19:06] [INFO] sleeping up to 10 seconds until next reconnection attempt
[2023-06-24 01:19:16] [INFO] checking state of node "dbhost" (ID: 1), 3 of 6 attempts
[2023-06-24 01:19:16] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=dbhost fallback_application_name=repmgr"
[2023-06-24 01:19:16] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2023-06-24 01:19:16] [INFO] sleeping up to 10 seconds until next reconnection attempt
[2023-06-24 01:19:26] [INFO] checking state of node "dbhost" (ID: 1), 4 of 6 attempts
[2023-06-24 01:19:26] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=dbhost fallback_application_name=repmgr"
[2023-06-24 01:19:26] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2023-06-24 01:19:26] [INFO] sleeping up to 10 seconds until next reconnection attempt
[2023-06-24 01:19:36] [INFO] checking state of node "dbhost" (ID: 1), 5 of 6 attempts
[2023-06-24 01:19:36] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=dbhost fallback_application_name=repmgr"
[2023-06-24 01:19:36] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2023-06-24 01:19:36] [INFO] sleeping up to 10 seconds until next reconnection attempt
[2023-06-24 01:19:46] [INFO] checking state of node "dbhost" (ID: 1), 6 of 6 attempts
[2023-06-24 01:19:46] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=dbhost fallback_application_name=repmgr"
[2023-06-24 01:19:46] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2023-06-24 01:19:46] [WARNING] unable to reconnect to node "dbhost" (ID: 1) after 6 attempts
[2023-06-24 01:19:46] [INFO] 1 active sibling nodes registered
[2023-06-24 01:19:46] [INFO] 3 total nodes registered
[2023-06-24 01:19:46] [INFO] primary node "dbhost" (ID: 1) and this node have the same location ("default")
[2023-06-24 01:19:46] [INFO] local node's last receive lsn: 0/7020000
[2023-06-24 01:19:46] [INFO] checking state of sibling node "dbhost3" (ID: 2)
[2023-06-24 01:19:47] [INFO] node "dbhost3" (ID: 2) reports its upstream is node 1, last seen 53 second(s) ago
[2023-06-24 01:19:47] [INFO] standby node "dbhost3" (ID: 2) last saw primary node 53 second(s) ago
[2023-06-24 01:19:47] [INFO] last receive LSN for sibling node "dbhost3" (ID: 2) is: 0/7020000
[2023-06-24 01:19:47] [INFO] node "dbhost3" (ID: 2) has same LSN as current candidate "dbhost2." (ID: 3)
[2023-06-24 01:19:47] [INFO] node "dbhost3" (ID: 2) has same priority but lower node_id than current candidate "dbhost2." (ID: 3)
[2023-06-24 01:19:47] [INFO] visible nodes: 2; total nodes: 2; no nodes have seen the primary within the last 4 seconds
[2023-06-24 01:19:47] [NOTICE] promotion candidate is "dbhost3" (ID: 2)
[2023-06-24 01:19:47] [INFO] follower node awaiting notification from a candidate node
utility@dbhost2:~$ [2023-06-24 01:20:47] [WARNING] no notification received from new primary after 60 seconds
What does our table tell us?
1
utility@dbhost3:~$ repmgr -f /etc/repmgr.conf cluster show
| ID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string |
|---|---|---|---|---|---|---|---|---|
| 1 | dbhost | primary | ? unreachable | ? | default | 100 | host=dbhost user=repmgr dbname=repmgr connect_timeout=2 | |
| 2 | dbhost3 | standby | running | ? dbhost | default | 100 | 1 | host=dbhost3 user=repmgr dbname=repmgr connect_timeout=2 |
| 3 | dbhost2 | standby | running | ? dbhost | default | 100 | 1 | host=dbhost2 user=repmgr dbname=repmgr connect_timeout=2 |
Now let’s bring back up the primary
[2023-06-23 17:22:31] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2023-06-23 17:22:33] [NOTICE] upstream is available but upstream connection has gone away, resetting
[2023-06-23 17:22:34] [NOTICE] reconnected to upstream node "dbhost" (ID: 1) after 167 seconds, resuming monitoring
You probably noticed that you are getting quite a lot of low level notifications from repmgr, lets fix that by adding the following lines to the bottom of /etc/repmgr.conf.
1
log_level=NOTICE
This will change the logging and will output it to a file as well, restart the service using sudo systemctl restart repmgrd.service
Setting up a witness
We will set up a postgres witness server, it is basically another isntance of postgres that will not participate in the replication but it wll however watch and make sure which servers are up in the network and it will be used for quorom. We are going to repeat the install of postgres and repmgr, however we will be using a different configuration file for repmgr here.
Do not do a standby clone, we will initialize it differently as this needs to be an independant node.
On your other server where you are planning to run a witness node, edit the /etc/repmgr.conf file, or create a new one.
1
2
3
4
5
node_id=4
node_name='witness'
conninfo='host=witness user=repmgr dbname=repmgr connect_timeout=2'
data_directory='/var/lib/postgresql/15/main'
log_level=NOTICE
After running the same standby replication steps as above, editing postgres.conf to change the data directory as well as the listen address, and lastly pg_hba.conf for the connection settings.
Once that is all done, we need to create the tables that are needed for the witness:
1
2
3
4
sudo su - postgres
createuser --superuser repmgr
createdb --owner=repmgr repmgr
psql -c "ALTER USER repmgr SET search_path TO repmgr, public;"
Once you finished the commands, lets restart the postgres service systemctl restart postgresql
Quick connectivity check
1
psql 'host=dbost user=repmgr dbname=repmgr connect_timeout=2'
Witnes registration
1
repmgr -f /etc/repmgr.conf witness register -h dbhost
Verification
1
repmgr -f /etc/repmgr.conf cluster show --compact
 Postgres/Repmgr Cluster showing witness
Postgres/Repmgr Cluster showing witness
Update sudoers file
1
2
3
Defaults:postgres !requiretty
postgres ALL = NOPASSWD: /usr/bin/systemctl stop postgresql, /usr/bin/systemctl start postgresql, /usr/bin/systemctl restart postgresql, /usr/bin/systemctl reload postgresql, /usr/bin/systemctl start postgresql, /usr/bin/systemctl stop postgresql
Configure automatic failover
1
2
3
4
5
6
7
8
9
10
primary_visibility_consensus=true
standby_disconnect_on_failover=true
repmgrd_service_start_command='sudo /usr/bin/systemctl start repmgrd.service'
repmgrd_service_stop_command='sudo /usr/bin/systemctl stop repmgrd.service'
service_start_command='sudo /usr/bin/systemctl start postgresql.service'
service_stop_command='sudo /usr/bin/systemctl stop postgresql.service'
service_restart_command='sudo /usr/bin/systemctl restart postgresql.service'
service_reload_command='sudo /usr/bin/systemctl reload postgresql.service'
monitoring_history=yes
log_status_interval=60
dry run test
1
repmgr -f /etc/repmgr.conf daemon start --dry-run
If you have started repmgr manually, it is time to kill it. We are going to change the /etc/default/repmgr file by running sudo nano /etc/default/repmgr and add the replace all the lines with these:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# default settings for repmgrd. This file is source by /bin/sh from
# /etc/init.d/repmgrd
# disable repmgrd by default so it won't get started upon installation
# valid values: yes/no
REPMGRD_ENABLED=yes
# configuration file (required)
REPMGRD_CONF="/etc/repmgr.conf"
# additional options
REPMGRD_OPTS="--daemonize=false"
# user to run repmgrd as
#REPMGRD_USER=postgres
# repmgrd binary
#REPMGRD_BIN=/usr/bin/repmgrd
# pid file
#REPMGRD_PIDFILE=/var/run/repmgrd.pid
Then we will run repmgr -f /etc/repmgr.conf daemon start ; make sure to do these changes on all the nodes.
If it doesn’t start, I found that sometimes I manually need to edit /etc/init.d/repmgrd and edit the line REPMGRD_ENABLED=no to REPMGRD_ENABLED=, then run the following commands:
1
2
3
sudo systemctl daemon-reload
sudo systemctl stop repmgrd.service
repmgr -f /etc/repmgr.conf daemon start
We are done!
You can go ahead and start testing by bringing the postgresql down, two commands you will need to remember are repmgr -f /etc/repmgr.conf cluster event - this will show you the latest events on the cluster that happened; And repmgr service status that’ll show you all the nodes and their status